Hadoop
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. This topic discusses how to work with Hadoop implementations.
This topic is specific to v11.2.040+ of our products.
![]() General information about Hadoop can be found at the official website.
General information about Hadoop can be found at the official website.
About Hadoop
Logi Analytics has strategic partnerships with the industry's Big Data technology leaders for analytical and Hadoop data stores: HP Vertica, Amazon Redshift, ParStream, Hortonworks, and Cloudera.
 Hadoop is designed to scale up
from single servers to thousands of machines, each offering local
computation and storage. Rather than rely on hardware to deliver
high availability, the library itself is designed to detect and handle
failures at the application layer, delivering a highly-available
service on top of a cluster of computers.
Hadoop is designed to scale up
from single servers to thousands of machines, each offering local
computation and storage. Rather than rely on hardware to deliver
high availability, the library itself is designed to detect and handle
failures at the application layer, delivering a highly-available
service on top of a cluster of computers.
Logi Info accesses data in real-time, through an ODBC connector in "Hive", a Hadoop component which facilitates querying and managing large datasets residing in distributed storage. Hive projects structure onto this data and queries the data using a SQL-like language called HiveQL. At the same time this language also allows traditional map/reduce programmers to plug in custom mappers and reducers when it is inconvenient or inefficient to express this logic in HiveQL.
Logi Studio's SQL Query Builder tool works well with HiveQL, to help build managed reports quickly and efficiently.
This topic presents techniques for connecting Logi Info applications to Hadoop implementations, such as Cloudera CDH4 and Hortonworks, and discusses the details of setting up Cloudera Kerberos authentication.
Connect to Hadoop
For a .NET Logi application, use the Connection.ODBC element to connect your Logi application to a the datasource.
![]() For a Java Logi application, use the Connection.JDBC element. Logi Info and Logi Report support Apache Hive 0.13.0 with Hortonworks 2.1 or Cloudera 5.0 Impala, and include supporting drivers and libraries for them.
For a Java Logi application, use the Connection.JDBC element. Logi Info and Logi Report support Apache Hive 0.13.0 with Hortonworks 2.1 or Cloudera 5.0 Impala, and include supporting drivers and libraries for them.
Special ODBC Drivers Required
For .NET applications, depending on which Hadoop implementation you're connecting to, you'll need to download and install either the Cloudera ODBC Driver for Impala or the Hortonworks Hive ODBC Driver. Select the proper driver version and Windows version (32- or 64-bit) for your application (a 32-bit driver is required for a 32-bit Logi app, and a 64-bit driver for a 64-bit app). You can install 32- and/or 64-bit drivers on a 64-bit machine.
The links provided point to web pages that include the drivers and installation guides. In general, all the default values can be used. After installation, restart the computer.
ODBC Data Source Configuration
For .NET applications, once you have a driver installed, you'll need to configure a ODBC data source to use it. This is done using the Windows ODBC Data Source Administrator utility.
On Windows platforms, this tool is typically launched from Start Menu![]() Administrative Tools
Administrative Tools![]() Data Sources, or Start Menu
Data Sources, or Start Menu![]() Control Panel
Control Panel![]() Administrative Tools
Administrative Tools![]() Data Sources. These shortcuts
launch the utility that matches the OS, i.e. on a 32-bit OS they launch the 32-bit utility, on a 64-bit OS, the 64-bit utility.
Data Sources. These shortcuts
launch the utility that matches the OS, i.e. on a 32-bit OS they launch the 32-bit utility, on a 64-bit OS, the 64-bit utility.
![]() If you want to configure a 32-bit data source on a 64-bit machine, you must use the 32-bit version of the Data Source Administrator. This is the source of many confusing problems when what appears to be a perfectly configured ODBC DSN does not work because it is loading the wrong kind of driver. You can't access the 32-bit Data Source Administrator from the Start Menu or Control Panel in 64-bit
Windows.
Instead, you must manually launch C:\WINDOWS\SysWOW64\odbcad32.exe.
If you want to configure a 32-bit data source on a 64-bit machine, you must use the 32-bit version of the Data Source Administrator. This is the source of many confusing problems when what appears to be a perfectly configured ODBC DSN does not work because it is loading the wrong kind of driver. You can't access the 32-bit Data Source Administrator from the Start Menu or Control Panel in 64-bit
Windows.
Instead, you must manually launch C:\WINDOWS\SysWOW64\odbcad32.exe.
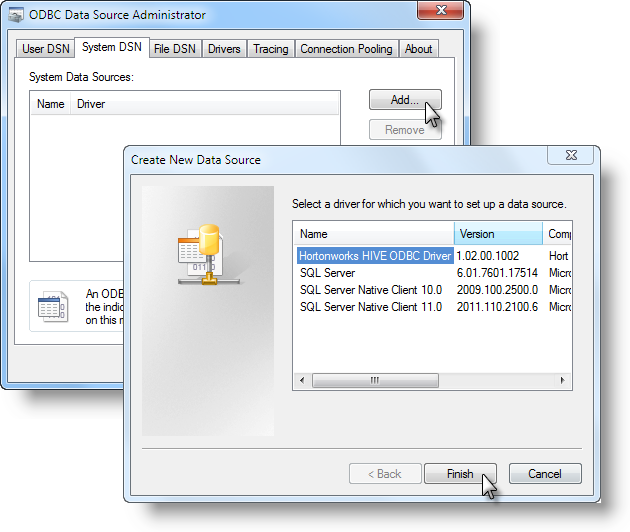
In the following examples, the Hortonworks driver will be shown, but the information also generally applies to the Cloudera driver. In the Data Source Administrator, shown above, select the System DSN tab and click Add. Select your new driver from the list and click Finish.

The Driver Setup dialog box, shown above, will be displayed. Fill-in the information as suggested above, making appropriate changes for the Cloudera driver. Detailed information about the purpose of each field is available in the Cloudera and HortonworksDSN Installation Guides. Authentication configuration will be discussed in a later section of this topic.
Once you've entered appropriate data, click Test to validate the connection. Click OK to save the DSN setup.

Your new data source should appear in the System DSN list, as shown above. Click OK to exit the utility. Now you're ready to use the driver.
Make the Connection
For .NET applications, use a Connection.ODBC element to make the connection.
![]() For a Java applications, use the Connection.JDBC element.
For a Java applications, use the Connection.JDBC element.
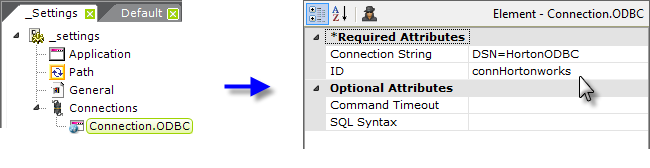
The example above shows a Connection.ODBC element in the _Settings definition, beneath the Connections element. Its Connection String attribute is then set to use the new ODBC datasource, by DSN name.
Retrieve Data
You can use DataLayer.SQL to retrieve data from Hadoop, and the Studio's SQL Query Builder tool can help you formulate a query. It can be invoked from the datalayer's Source attribute.
![]() DataLayer.Active SQL is not currently available for use with this datasource.
DataLayer.Active SQL is not currently available for use with this datasource.
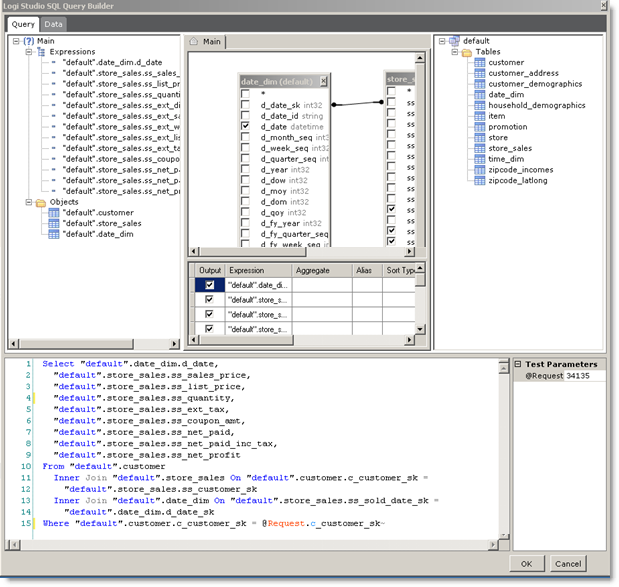
As mentioned earlier, Hadoop uses HiveQL which is based on standard SQL syntax but has a number of very important differences that you should be aware of as you create your queries. Please refer to the Hive Language Manual for more information. After the data is retrieved, you may condition, filter, and shape it just as you would any other datalayer data.
![]() Another Studio tool, the Database Browser, is not compatible with HiveQL.
Another Studio tool, the Database Browser, is not compatible with HiveQL.
Once data has been retrieved into the datalayer, it can be manipulated using any of the elements typically used to filter, aggregate, and condition data. For more information, see the Manipulating the Datalayer section of our Introducing Datalayers document.
Cloudera and Kerberos Authentication
Logi Info has been certified with Cloudera's CDH4 using Kerberos as a method to authenticate database access. Hortonworks is not certified at this time.
Kerberos security should be enabled at the cluster server. MIT's kfw-4.0.1-amd64.msi must be installed on the Logi application web server, and then the file krb5.conf should
copied from the Kerberos server to the web server. Save it to the following folder and change its file extension as shown: C:\ProgramData\MIT\Kerberos5\krb5.ini
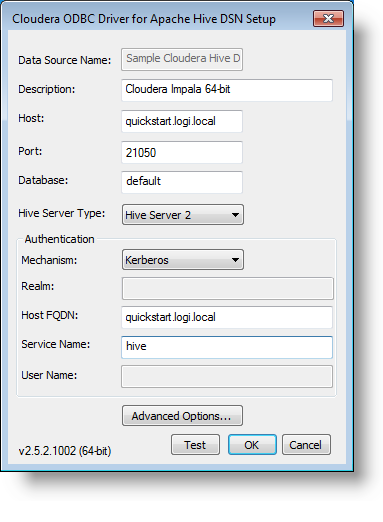
A typical DSN setup is shown above. Note that Kerberos will not work with IP addresses in place of a Host name.
For this example, a Hadoop account was created for "logixml" and added to the Kerberos domain ("CLOUDERA"). Then this account is used in the Impala configuration to allow access as the Kerberos principal user
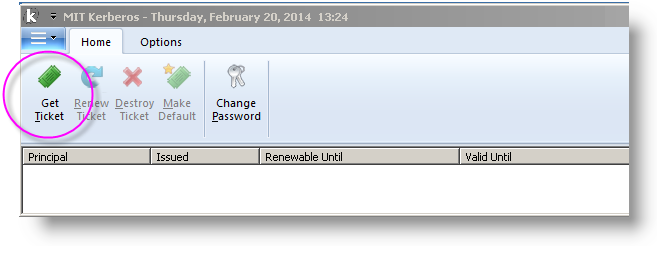
The MIT Kerberos Ticket Manager utility, which is part of the kfw-4.0.1-amd64.msi installation and shown above, is used to get a Kerberos ticket.
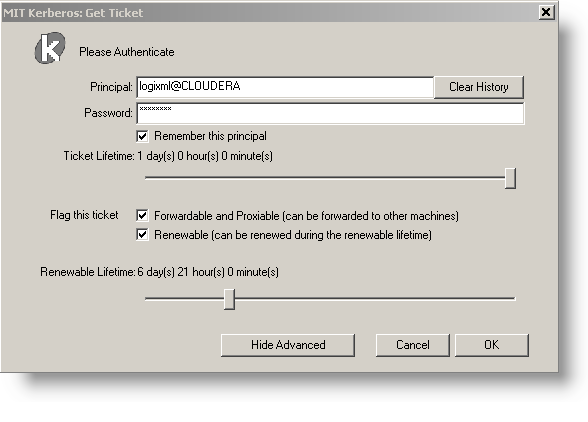
On the server, the MIT Kerberos Get Ticket application is used to obtain the correct credentials from the Kerberos domain controller.

Once the credentials are obtained, they appear in the Ticket Manager, as shown above.