Web Page Screen Scraping
The DataLayer.Web Scraper element "scrapes", or retrieves, content from within web pages and organizes it into the row/column datasets usually found in datalayers. This provides an easy way for developers to automate the collection and use of data published on other web sites or in HTML files. This topic discusses techniques for using the datalayer.
- About Web Page "Scraping"
- Use "Get XPaths" and Web Scraper Table
- Use Web Scraper Rows and Web Scraper Column
About "Web Page Scraping"
"Screen scraping" has been around for a long time; it's the process of extracting data from the text on a display screen, usually based on fields or screen regions. A key issue is that the data is intended to be viewed and is therefore neither documented nor structured for convenient parsing. In the age of the Internet, the term has also come to apply to the same process with web pages. In many cases, complicated parsing code is required.
However, the Logi approach makes the process fairly easy. Generally, in a Logi application, the target HTML web page is read (the entire page, not just the portion displayed), transformed into XML, and then parsed based on XPath identifiers. Data formatted into tables, and even in less-structured blocks of text, can readily be parsed and served up to the report developer in the standard Logi datalayer row/column structure. The data can then be further processed (filtered, grouped, aggregated, etc.) using all the usual datalayer child elements. This is all done using the DataLayer.Web Scraper element and its child elements.
![]() The DataLayer.Web Scraper element is not available in Logi Java applications.
The DataLayer.Web Scraper element is not available in Logi Java applications.
For purposes of convenience, this topic refers to "HTML files" but file extensions are not really important; if the file will render to a web page, the datalayer will use it. Pages with .htm, .html, xhtml, .mht and other extensions are all valid.
One of the keys to this process is specifying the XPath parsingidentifiers and DataLayer.Web Scraper provides a mechanism for assisting developers in selecting them, as discussed in the next section.
Note that this topic illustrates techniques by referring to public web sites. While we make an effort to stay aware of them, these sites may change their coding from time to time without our knowledge, invalidating the actual data and values depicted, so you may not be able to achieve the identical results. The techniques themselves, however, remain valid.
Use "Get XPaths" and Web Scraper Table
The DataLayer.Web Scraper element has an attribute named Get XPaths. During development, when this attribute is used, the target HTML page is read and transformed into XML, then a reference document is created that lists all of the XPath identifiers and their values. Looking through this document, the developer can quickly see, for example, the XPath tag name for a table with the desired data.
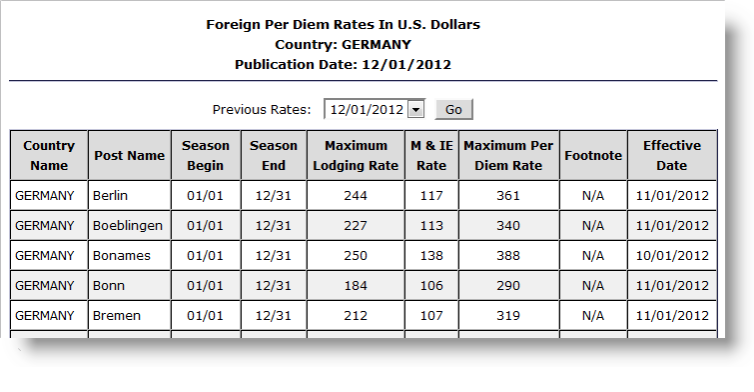
The example above shows part of the U.S. State Department web site page that publishes per diem rates. The following example shows how to use DataLayer.Web Scraper to get the XPath tags needed to parse this page.
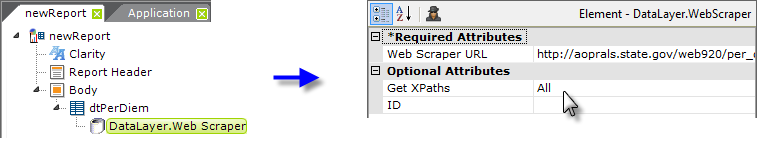
As shown above, add a Data Table element with a DataLayer.Web Scraper child element the report definition. Set the datalayer's Web Scraper URL attribute value to the URL of the target web page:
http://aoprals.state.gov/web920/per_diem_action.asp?MenuHide=1&CountryCode=1089
and set its Get XPaths attribute to All, which causes the development reference document to be created.
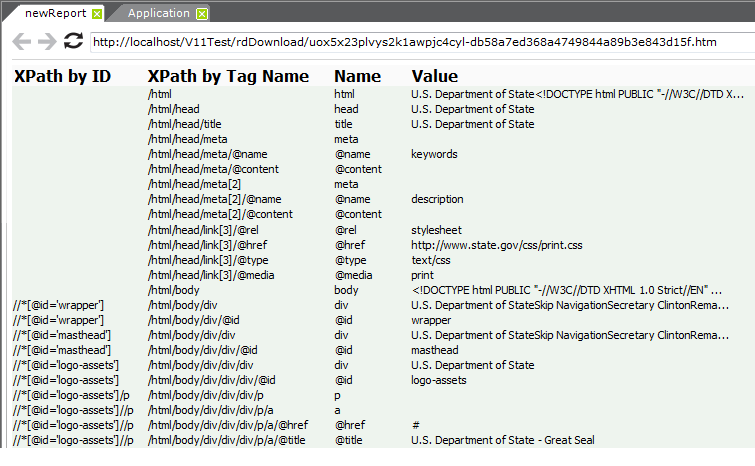
Preview the report in Studio, and examine the XML nodes reference document, shown above.
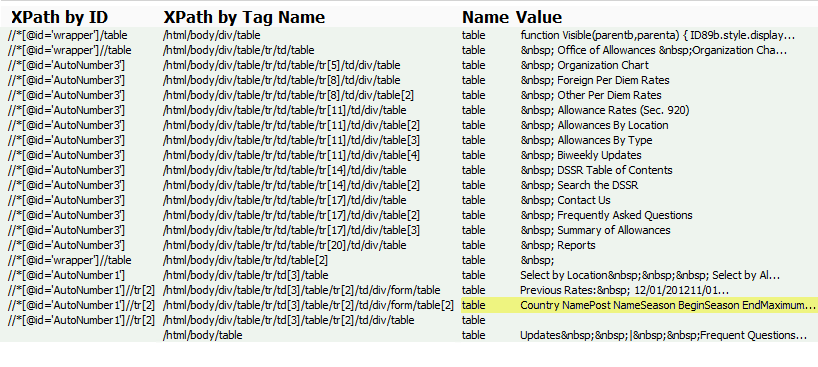
Locate the desired nodes by filtering out everything else, in this case everything except tables. To do this, go back to viewing the definition and enter //table into the Get XPaths attribute and then preview the definition again. Look through the Values column: tables are identified by their headings, not their row data, so the target table has to have distinctive headings. The table we want is shown above highlighted.

Next find, select, and copy the table's entire XPath by Tag Name value, highlighted above.
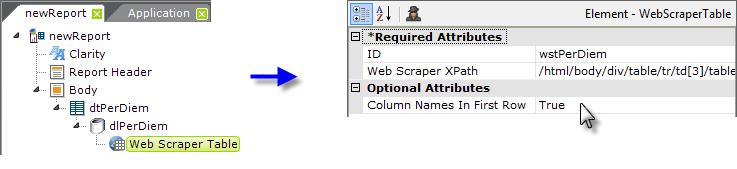
Next, back in the definition, clear the datalayer's Get XPath attribute value. Then add a Web Scraper Table child element beneath the datalayer and paster the XML tag copied from the reference document into its Web Scraper XPath attribute, as shown above, right. The complete value is:
/html/body/div/table/tr/td[3]/table/tr[2]/td/div/form/table[2]
And also set the Column Names In First Row attribute value to True.
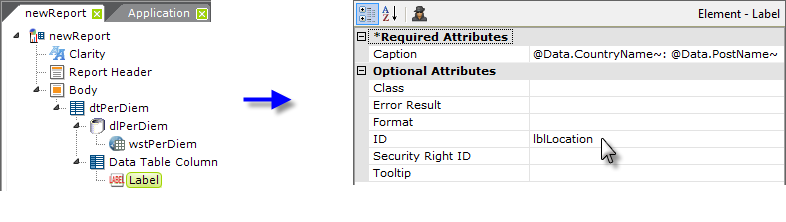
Finally, as shown above, add Data Table Column and Label elements to display the data:The column names in the datalayer, for use with @Data tokens, are the names seen in the XPath reference document values, with any embedded spaces removed. In this example, that's CountryName, PostName, SeasonBegin, SeasonEnd, etc.
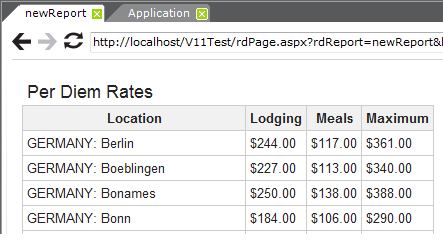
When previewed, as shown above, the report display the table with the desired data from the target web site.
Use Web Scraper Rows and Web Scraper Column
What if the target data on a web page is not in a table? In that case, two other elements, Web Scraper Rows and Web Scraper Column, can be used with DataLayer.Web Scraper to extract the data.
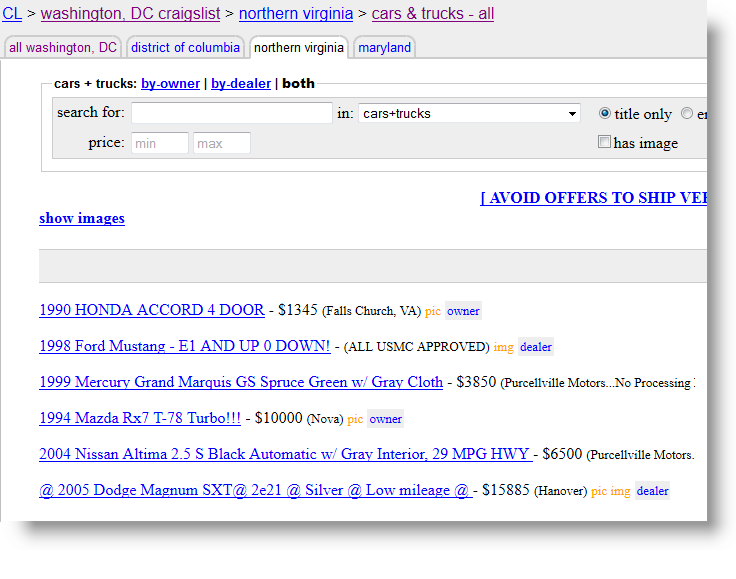
Part of the Craig's List web site, where cars are advertised for sale, is shown above. Our goal in this example is to display data from this site, in a Text Cloud chart, indicating the most common locations specified in these ads.
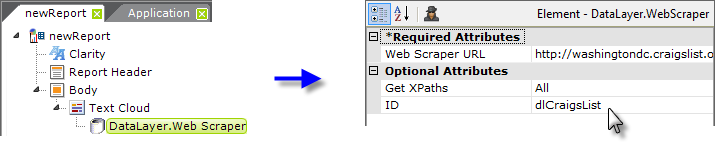
As shown above, first add a Text Cloud element, and beneath it, a DataLayer.Web Scraper element to the report definition.
The Text Cloud element has three required attributes: an element ID, and a Cloud Label Column and Cloud Size Column. Give it an ID and, for now, enter two dummy values ("a" and "b", for example) in the two Column attributes. Set the datalayer's attributes as shown above. The complete target URL is: http://washingtondc.craigslist.org/nva/cta/
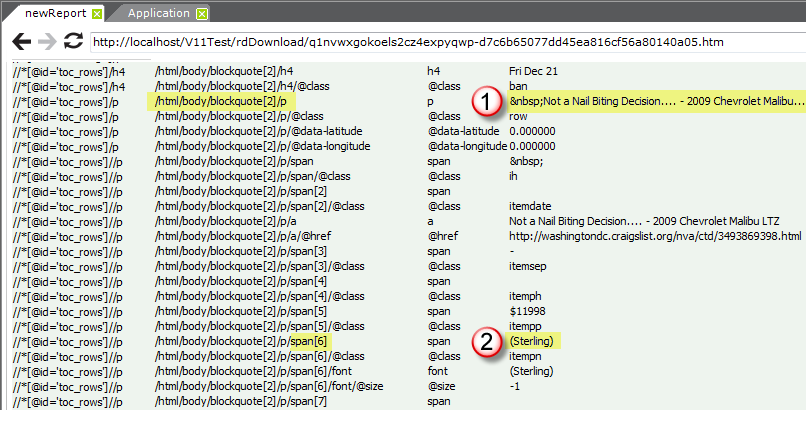
As before, preview the site and the XML nodes reference document, shown above, will be displayed. Scroll down through it, carefully looking for the start of the first actual car advertisement data block (this may not match the first ad you saw when you browsed the site). You'll have to scroll through all the stuff in the page header, search tools, title, etc.
When the first occurrence of the desired ad data block (1) is located, copy its XPath by Tag Name value (highlighted in the second column). This will value be used in the Web Scraper Rows element.
Next, because we're building a Text Cloud based on the locations mentioned in the ads, look downward in the Value column until you find the first occurrence of the location data (2). Note the part of its XPath by Tag Name value that is relative to the first XPath value we found:
1st value: /html/body/blockquote[2]/p
2nd value: /html/body/blockquote[2]/p/span[6]
Relative value: span[6]
This relative value will be used in the Web Scraper Column element.
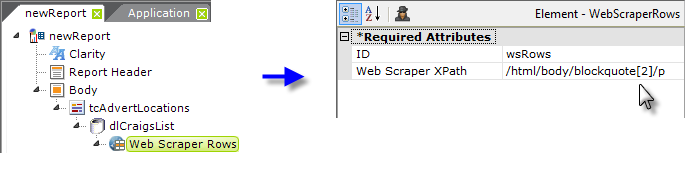
Back in the definition, clear the datalayer's Get XPaths attribute, and add a Web Scraper Rows element beneath the datalayer. Its Web Scraper XPath attribute is set to the first XPath value located earlier, as shown above.
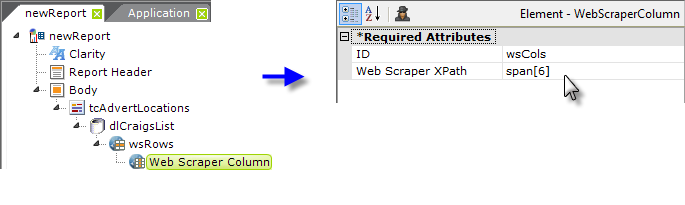
Beneath the Web Scraper Rows element, add a Web Scraper Column element. One of these is needed for every column to be returned in the datalayer. As shown above, its Web Scraper XPath attribute is set to the relative value noted earlier. This column in the datalayer will hold the location values.
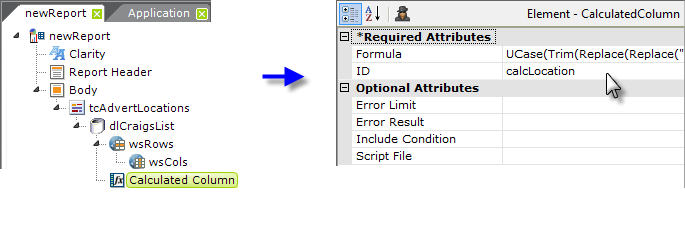
Next, add a Calculated Column element to clean up the data, adjust its case, etc. to bring some consistency to the data,
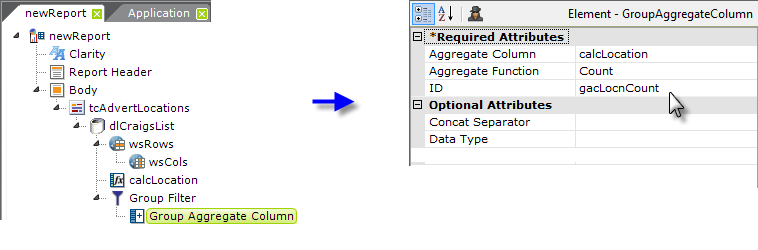
and grouping elements to group it by location and produce a count or frequency value we can use in the Text Cloud.
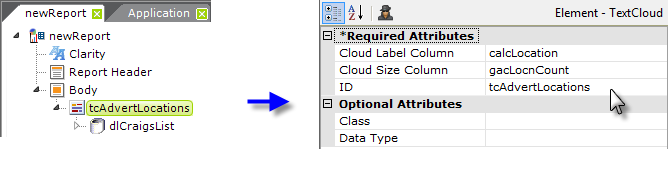
Finally, return to the Text Cloud element's Column attributes and set them to the proper datalayer columns, as shown above.

When browsed, the final report produces the text cloud shown above, with larger fonts denoting the locations from which cars are offered for sale on Craig's List more frequently.
Once this report has been defined, it will retrieve the latest data from the web page each time it is run. If the web site is structurally redesigned, however, then the report may have to be updated with new XPath values.