Using Web Scraper Rows and Web Scraper Column
What if the target data on a web page is not in a table? In that
case, two other elements, Web Scraper Rows and
Web Scraper Column, can be used with DataLayer.Web Scraper to
extract the data.
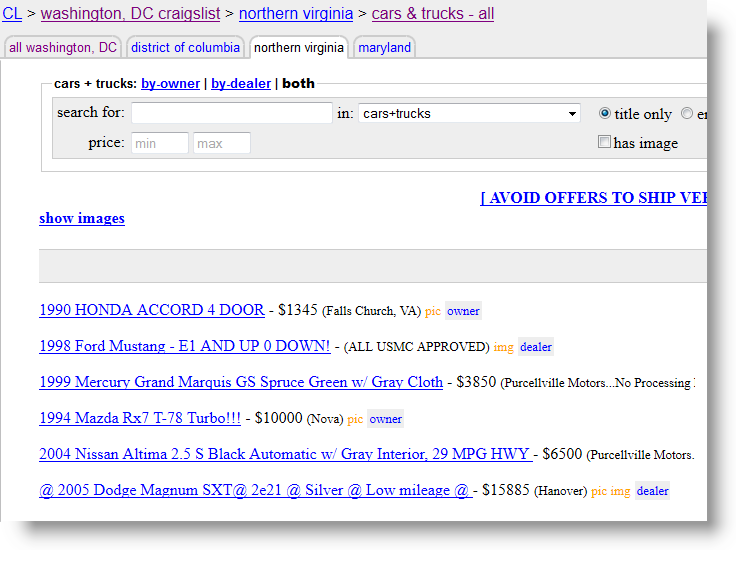
Part of the Craig's List web site, where cars are advertised for
sale, is shown above. Our goal in this example is to display data from
this site, in a Text Cloud chart, indicating the most common
locations specified in these ads.
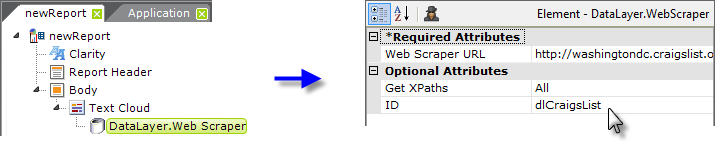
As shown above, first add a Text Cloud element, and beneath it, a DataLayer.Web Scraper element to the report definition. The Text Cloud element has three required attributes: an element ID, and a Cloud Label Column and Cloud Size Column. Give it an ID and, for now, enter two dummy values ("a" and "b", for example) in the two Column attributes. Set the datalayer's attributes as shown above. The complete target URL is: http://washingtondc.craigslist.org/nva/cta/
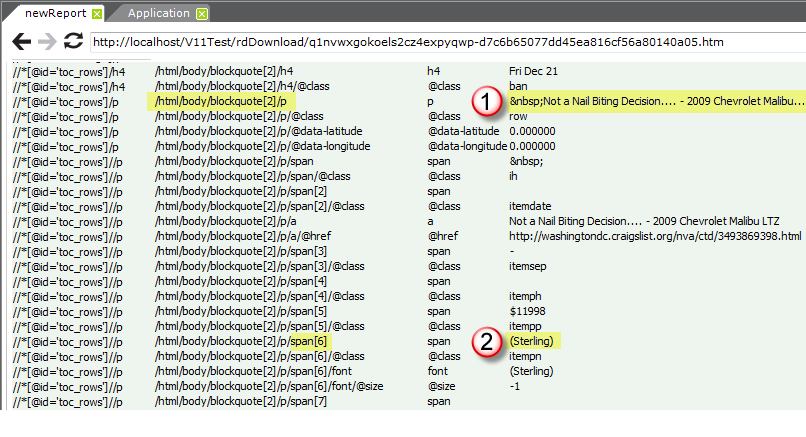
As before, preview the site and the XML nodes reference document, shown above, will be displayed. Scroll down through it, carefully looking for the start of the first actual car advertisement data block (this may not match the first ad you saw when you browsed the site). You'll have to scroll through all the stuff in the page header, search tools, title, etc.
When the first occurrence of the desired ad data block (1) is located, copy its XPath by Tag Name value (highlighted in the second column). This will value be used in the Web Scraper Rows element.
Next, because we're building a Text Cloud based on the locations mentioned in the ads, look downward in the Value column until you find the first occurrence of the location data (2). Note the part of its XPath by Tag Name value that is relative to the first XPath value we found:
- 1st value: /html/body/blockquote[2]/p
2nd value: /html/body/blockquote[2]/p/span[6]
Relative value: span[6]
This relative value will be used in the
Web Scraper Column element.
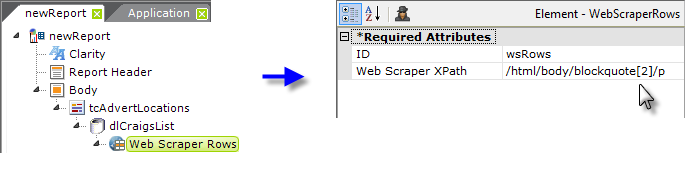
Back in the definition, clear the datalayer's Get XPaths attribute, and add a Web Scraper Rows element beneath the datalayer. Its Web Scraper XPath attribute is set to the first XPath value located earlier, as shown above.
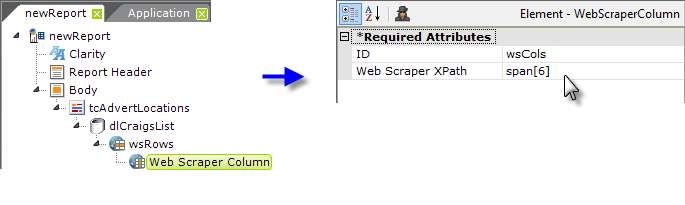
Beneath the Web Scraper Rows element, add a
Web Scraper Column element. One of these is needed for every column
to be returned in the datalayer. As shown above, its
Web Scraper XPath attribute is set to the relative value
noted earlier. This column in the datalayer will hold the location
values.
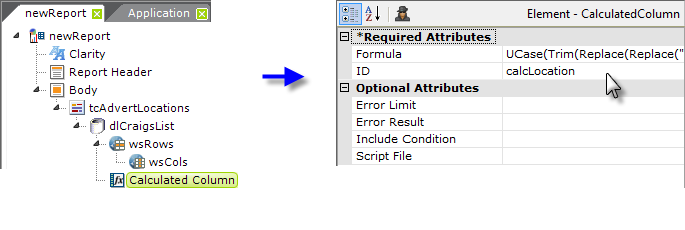
Next, add a Calculated Column element to clean up the data, adjust its case, etc. to bring some consistency to the data,
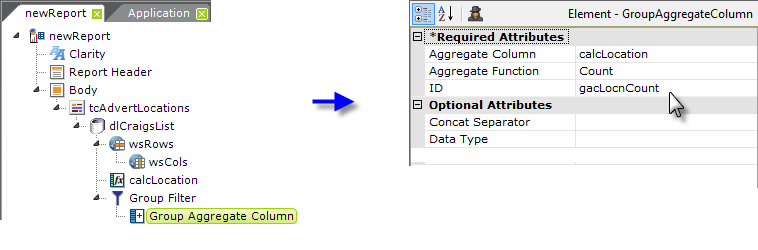
and grouping elements to group it by location and produce a count
or frequency value we can use in the Text Cloud.
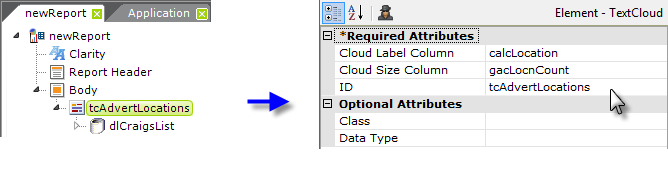
Finally, return to the Text Cloud element's Column attributes and
set them to the proper datalayer columns, as shown above.

When browsed, the final report produces the text cloud shown above, with larger fonts denoting the locations from which cars are offered for sale on Craig's List more frequently.
Once this report has been defined, it will retrieve the latest data from the web page each time it is run. If the web site is structurally redesigned, however, then the report may have to be updated with new XPath values.