Grouping Data with Subdata Layers
The first step in creating drill-down functionality, like that shown in "Drilling Down" using a SubData Table, is to include More Info Row element and Sub-Data Table elements in your report.
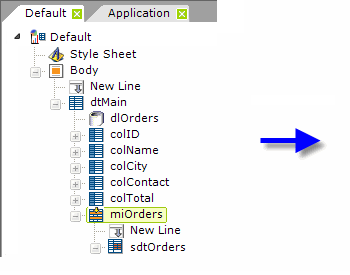
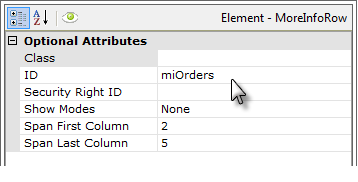
The definition example shown above includes a main Data Table, the More Info Row element ("miOrders") and a SubData Table element ("sdtOrders"). The configuration of the More Info Row's attributes is shown.
The More Info Row Column element can be used to closely align More Info Row columns with the columns of its parent table. When this element is used, the More Info Row element's Span First Column and Span Last Column attributes are left blank, and the More Info Row Column element's Column Span attribute is used instead to control spanning of parent table columns.
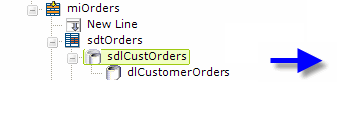
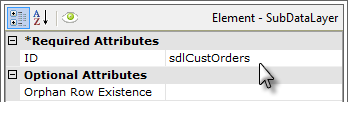
Now a Subdata Layer element ("sdlCustOrders") has been added beneath the SubData Table; it provides a container for a regular datalayer element ("dlCustomerOrders").
The datasource used by the regular datalayer element beneath a Subdata Layer element has to be the same as the datasource used by the main Data Table. In other words, they both get their data from the same place. This generally means that the same type of regular datalayer element will be used for both, so, if a DataLayer.SQL element is used to retrieve data for the main table, then a DataLayer.SQL element will be used with the Subdata Layer element.
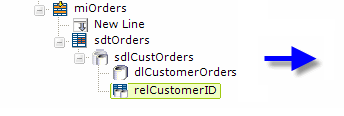
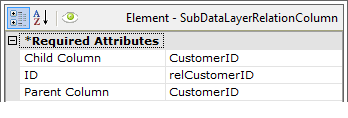
Finally, a Subdata Layer Relation Column element is added beneath the Subdata Layer element. Its attributes are set, as shown above, to create the relationship between the data in the main table's datalayer (Parent Column) and the data in the sub-datalayer (Child Column).
The practical effect of this is to create a single, hierarchical XML data object that contains child data records interspersed within their parent data records.
Depending on the data returned to the sub-datalayer, it's possible that some child rows will not have a matching parent row; these are "orphan rows". It may be possible to ensure that there will be no orphan rows through, for example, the right SQL query or external validation of the data. If that's the case, then disabling error-checking in the Subdata Layer, by setting its Orphan Row Existence attribute to False, may yield faster performance. Otherwise use the
default, True, to prevent errors.
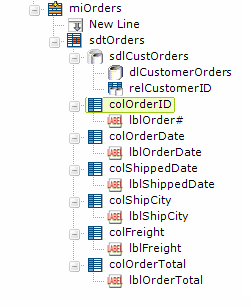
The definition is completed by adding the Data Table Column and Label elements that are typical for any Data Table, as shown above. Keywords: SubDataLayer, SubDataTable, SubDataLayerRelationColumn